

How Much Duplicate Content is Acceptable for Google?
It is estimated that approximately 25 to 30 percent of all web content is duplicate. That’s because different quotes, case studies, and tips are shared across the Internet on different websites.
But that’s usually considered “duplicate content” that should be penalised by Google. It’s important to look at that in full context.
However, if you do duplicate content with the idea of plagiarising it, that usually leads to Google penalties. In addition to plagiarism, creating content that’s not unique to each page on your own website can also lead to the same problem.
The second scenario is something that local businesses often run into.
When local businesses have to create different product or service pages, or different location-specific landing pages, they run into the potential problem of duplicating content.
The general rule is that such duplicate content must be avoided.
But … what percentage equals duplicate content for Google?
Is it 10%? 20%? 50%?
This was the question that Bill Hartzer on Twitter recently asked Google’s John Muller.
“Is there a percentage that represents duplicate content?
For example, should we be trying to make sure pages are at least 72.6 percent unique than other pages on our site?
Does Google even measure it?”
Google’s John Mueller responded that there is no fixed percentage or number that Google uses to measure duplicate content.“There is no number (also how do you measure it anyway?),” replied John Mueller.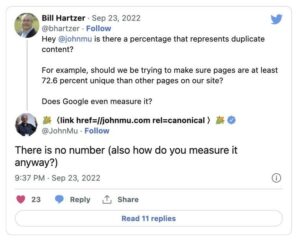
So, how does Google detect duplicate content?
If there is no specific number, how does Google exactly detect duplicate content?
We have 2 quotes from Google search experts that may share some insights into it.
The first bit of information came from Matt Cutts in 2013. According to Matt:
“[When Google finds bits and pieces of duplicate content on a web page, they] try to group it all together and treat if it is just one piece of content.
“It’s just treated as something that we need to cluster appropriately. And we need to make sure that it ranks correctly.”
Matt also explained that Google first (1) chooses which pages to show on the SERPs for a specific query and (2) then filters out duplicate pages so the user experience can be improved.
The second bit of information came from Gary Illyes in 2020 during the Search Off the Record podcast, while discussing if duplicate content detection and canonicalisation are the same things.
Gary Illyes explained:
“First, you have to detect the dupes, basically cluster them together, saying that all of these pages are dupes of each other, and then you have to basically find a leader page for all of them.
And that is canonicalization.
So, you have the duplication, which is the whole term, but within that, you have cluster building, like dupe cluster building, and canonicalization.“
Then Gary Illyes explained how Google detects duplicate content:
“So, for dupe detection, what we do is, well, we try to detect dupes.
And how we do that is perhaps how most people at other search engines do it, which is, basically, reducing the content into a hash or checksum and then comparing the checksums.”
You can read more about checksums here.
Here are a few resources on detecting duplicate content:
More importantly, however, local businesses should focus on avoiding duplicate content in the first place.
Here are a few tips to help you with that:
- Organize your content in thematically related topic clusters with unique H1 headings and meta titles.
- Redirects duplicate pages if you only want to keep one version.
- If you want to keep both versions on your website for some reason but want Google to only index one page, use canonicalization.
- For the master versions, always use a self-referential canonical tag.
- Avoid parameterized URLs as Google can index parameterized URLs on the SERPs in addition to the main URL, creating duplicate versions of a page in the Google index.
Related Posts:







